Some time ago I was involved in a software project founded by the company I have been successfully cooperating with for number of years. This company specializes in servicing and modernizing military equipment and instruments (mostly aviation) and I was responsible for implementing a piece of software integrated with the hardware platform designed by this company. During one of the catch-up meetings I was asked by the project lead engineer to share my thoughts on the route they could take to start developing software solutions running on embedded platforms as well as on desktop (two birds with one stone, one may say).
These days picking ONE, multi purpose technology is actually more difficult than it seems and the fact that web oriented solutions are getting more and more popular does not make things any easier. That is why I decided to publish my thoughts on this subject.
Background
To fully understand what I was asked for it is important to know some context. The company’s tower I have been working with hires a number of highly qualified, seasoned electronics engineers. Unlike tech departments in most of the companies I have seen so far, the average age of engineer is quite high and people use to work in the same company for more than just a couple of years (working with military and aviation especially is hard, one needs to spend few years as a junior to know what is going on). Engineers involved in the project had experience with the “old school” digital electronics, microcontrollers programmable with low level programming languages such as assembler and high level programming languages like C/C++ and VHDL (books I used to learn programming from defined C and C++ as high-level languages but I think it is not the case as languages like Scala, C#, Python are around). With this set of tools they were delivering top quality solutions for military for years although, as systems they were developing were getting more complex, they found themselves to be in a position where using programmable microcontrollers and low-level hardware communication protocols was just not enough. They needed to master higher level tools such as OS (Operating Systems), Ethernet protocols, multithreading and GUIs (Graphic User Interfaces) – things that have been around for years in desktop development world.
Picking the right technology
In IT things are never simple – despite what the salesmen say, silver bullets just do not exist. There is a lot of marketing hype around new technologies, older technologies (even if still widely used) are lying in the dank corners, not mentioned by any of cool technology “evangelists” (that being said, it seems like IT these days is driven more by marketing and less by the engineering concerns and real specialists). Nevertheless, picking a technology and investing time to master you have to proceed with caution. To approach this methodically, we set back with the lead engineer and listed requirements that ideal platform should met. Here are few of them:
Support for GUI
The new platform was intended to be used in a wide variety of scenarios, including communication with hardware as well as providing user interaction. There are probably dozens (or more) technologies meeting these requirements but, based on my personal experience, I have narrowed this set to only three-ish mainstream options:
- Microsoft .NET (Windows Forms / WPF) / Mono;
- Qt;
- Java (Swing / JavaFX).
I am aware that there are more libraries, languages and frameworks but they are either niche, not mature enough or I had no experience with them. Plus, you have to start with something. If we had not found suitable technology, we would have continued with longer list.
One may notice that I have not listed any HTML/JS frameworks such as AngularJS, Backbone etc. which are very popular these days. Although it seems possible to use them to provide industry quality GUIs (HTML/JS components rendered by the browser installed on the embedded OS, displayed on 7” LCD touch screen etc.) but it also seems like a big overhead – performance wise – and would force the team to acquire much more knowledge (HTML, stylesheets, JavaScript). Besides, it would solve only part of the problem as some backend technology would have to be used anyway, even if it was NodeJS, it would be some additional framework to cope with.
It had to be there for “a while”
Considering the character of the company, and the team (time required to train new member, average age of the crew – yep, it takes longer to learn new stuff when you are over 40 or 50 years old), it was one of the crucial requirements. Investing months in getting acquainted with the new technology, running tests, integrating with hardware, writing drivers, just to say good-bye after a couple of years and start from scratch again – this risk was not acceptable.
To estimate maturity of the technology and its adoption, it is a good idea to start with Google Trends.
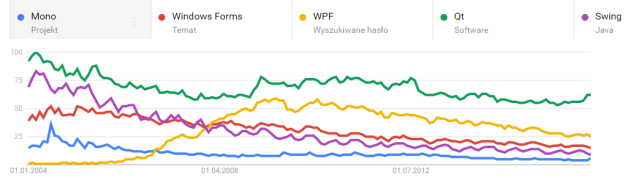
It seems like Qt is the big winner. Not only people’s interest in this platform is sustained, it is the number #1 if you compare number of search queries with other options. The most likely reason is its wide adoption in the IoT and embedded worlds. You can find Qt implemented software in various devices, on board computers of modern cars, trams, trains etc.
Compared to Qt, other technologies look rather off-colour. I think the reason for that was that these technologies were widely adopted in desktops applications, which are not very popular these days in favor of web frameworks. Most of the new projects are started with browsers and mobile devices in mind.
Microsoft, on the other hand, is a bit (un)famous for its products depreciation policy. I remember the big hype around XNA, Silverlight and other frameworks that were deprecated. For companies using these technologies it was a massive cockup. In addition to that, it seems like Microsoft is not willing to compete with Qt at this field. It has been investing in IoT market recently but I think it is more like an attempt to popularize their platform amongst the students and enthusiasts, rather than top industry specialists. Even though Windows Forms and WPF are widely adopted, they both depend on Win32 and I would expect seeing problems developing with these platforms in the future.
Java, as opposed to .NET, was always very serious about backward compatibility. I think this is very important and allows us to assume that Java based frameworks will not get deprecated in the near future. Furthermore, Java GUI frameworks do not directly depend on any specific OS but rather on the Java VM which is generally a good thing, although comes for the price of performance.
Mono looks like it never really kicked-off although worth further investigation, as it is an interoperable port of decent .NET platform.
Interoperable
This is where both Qt and Java shines most. Both of these frameworks allow software engineers to target multiple operating systems and their embedded versions.
.NET and Mono, on the other hand, were defeated. .NET framework can be used only on Windows based platforms (Microsoft’s approach to interoperability is like Henry Ford’s approach to car color customization was). But what about Mono? It most certainly can be run on wide variety of systems but it does not implement Windows Forms nor WPF! So yes, you can develop on multiple platforms with Mono as long as you do not need any GUI. One could use third party ports and bindings (like Gtk#) but it introduces additional effort and make things much more complicated (plus relying on a port on top of another port – you get the idea…).
Easy to use
I think that if you are starting up with the completely new technology you have more than enough problems already, hence I think ease of use is very important factor. I am aware that simplicity very often comes for a price of limited flexibility but the goal was not to find the simplest solution – it was rather to find technology stack that required as few extra steps to get up and running as possible. After running some tests with both Qt and Java Swing on an arbitrary embedded board I had to admit that Java and its GUI framework – Swing – really shines.
After few hours I was able to develop Java Swing applications with NetBeans IDE, run them on my desktop (with Windows 7 installed) and easily deploy them on my embedded, Linux based board. There were no issues with setting up a debugger (so I could remotely debug code running on embedded board with Debian from Windows desktop station – pretty neat!). Getting Swing components to be displayed on touch LCD screen was not too hard either (a solution to the only issue I had is described HERE).
Achieving the same with Qt was not as easy. First of all, a de-facto standard to develop with Qt is C++ which requires some extra steps. You have to use so called “tool chains” to develop on one architecture and deploy to the other (PC -> ARM etc.). This requirement did not allow me to use Windows as a development and compilation platform. I had to install Linux on VM and set up the toolchain there. Additionally, I had to compile Qt for my specific embedded board setup. After spending much more time than with Java, I finally got it working and I was pretty happy with the results. I could develop applications with Qt Creator IDE on my desktop (VM with Linux installed which was slightly inconvenient), run it locally, deploy to the device and debug it remotely.
Based on my experience, I would say that getting up and running with Java Swing is much easier than with Qt (especially if you are not a Linux professional). Having a Java Runtime Environment solves lots of problems for you, makes it easier to develop for multiple platforms (for the price of execution performance, for sure).
Summary
I think I did my best to provide as much rationale as possible – and I know it was very subjective and based on my personal experience and observations.
I would definitely not proceed with .NET nor Mono. Although a decent platform, .NET is bound to the Microsoft Windows OS (which is far from being a de-facto standard in the world of embedded devices and IoT). Mono, on the other hand, seems to be a bit immature, does not provide out of the box GUI framework (although there are some other components like Gtk#) and will always be one step behind .NET. There was a lot of hype around Xamarin recently but it is targeted to mobile devices rather than industry standard embedded platforms.
Java and Swing seemed to be a good choice. Java is very widely spread in the industry, it allows developers to target multiple platforms and there are plenty of books, courses and other materials, including on-line. Swing, even though quite mature, is not deprecated and I am convinced that it will be supported in future JRE releases (as I stated before in this post, Java is known for its backward compatibility). And last but not least, getting it up and running on an arbitrary device was much easier compared to Qt.
Qt would be also a very good fit as it is interoperable, very popular in the industry and very powerful. Preparing a development environment is slightly more complicated but it pays off when it comes to performance (no VM). The other thing I like about Qt is that it seems to be the only platform being so actively developed. I have a feeling that both Microsoft and Oracle are ignoring desktop GUI developers which could be easily picked up and adopted by embedded UI devs – which is a big shame IMHO. The downside of Qt is that licensing is quite costly. I am not saying it is a deal breaker but it is definitely something to take into consideration.
As stated before, this whole post is very subjective. All opinions stated are my own and they were based on my personal experience and observations. I am most certainly not paid by any of listed companies– nor their competition – to state any opinions (that would be some easy money, would it not?).
 The answer is: because they can afford, they can benefit from it, there are right tools to be used and people who know how to use them.
The answer is: because they can afford, they can benefit from it, there are right tools to be used and people who know how to use them.



